MacBook Air 跑不動的活,我丟給家裡那台 MBP 代勞




我有一個天天在用的 /transcriber skill,把錄音或影片丟給它,就會吐出一份逐字稿。這兩天我把它的底層整個換掉:表面上用法完全沒變,同一個指令照打,但真正在跑 Whisper 模型的,已經不是我手上這台 MacBook Air,而是放在家裡、一直開著的那台 MacBook Pro。
skill 一樣在我的 MBA 上觸發,但它會把音檔送到 MBP,在那邊用 Apple Silicon 的 Metal GPU 跑 MLX(Apple 自家的機器學習框架)版的 Whisper,再把逐字稿傳回來。我這台筆電從頭到尾只負責「發號施令」跟「等東西回來」,重活一點都沒碰。
先講清楚前提:這套做法要成立,得你手邊剛好有第二台、一直開著又還算夠力的機器(我這邊是家裡那台 MBP)。沒有的話,下面就當個架構思路參考。
為什麼不乾脆在筆電上跑就好
最直接的原因:我的 MBA 扛這個真的很勉強。Whisper 的大模型(large-v3)光載進記憶體就要好幾 GB,我這台隨身機記憶體本來就吃緊,再開這種模型,其他工作全被排擠。
而且用 CPU 硬跑,整台機器會燙得像暖暖包、風扇狂轉,速度還比 GPU 慢上好幾倍。把這件事整包丟到 MBP、用它的 Metal GPU 跑,一個小時的錄音大概十分鐘就轉完,而我的筆電全程溫度正常,照常做我的事,完全無感。
重點是「同一個模型」被重複利用
那台 MBP 在我家本來就有任務——它一直開著跑我在 Day 141 介紹過的 Vexa(會議轉錄服務),記憶體裡早就常駐著一個 Whisper 模型。
所以 /transcriber 預設不是自己再去開第二個模型,而是直接呼叫那台 server,借用已經暖好的那一個。結果就是:我多了一個「隨時轉錄檔案」的能力,卻沒有因此多佔掉一大塊記憶體。一台機器、一個模型,同時扛起「線上會議即時轉錄」跟「離線檔案轉錄」兩件事。
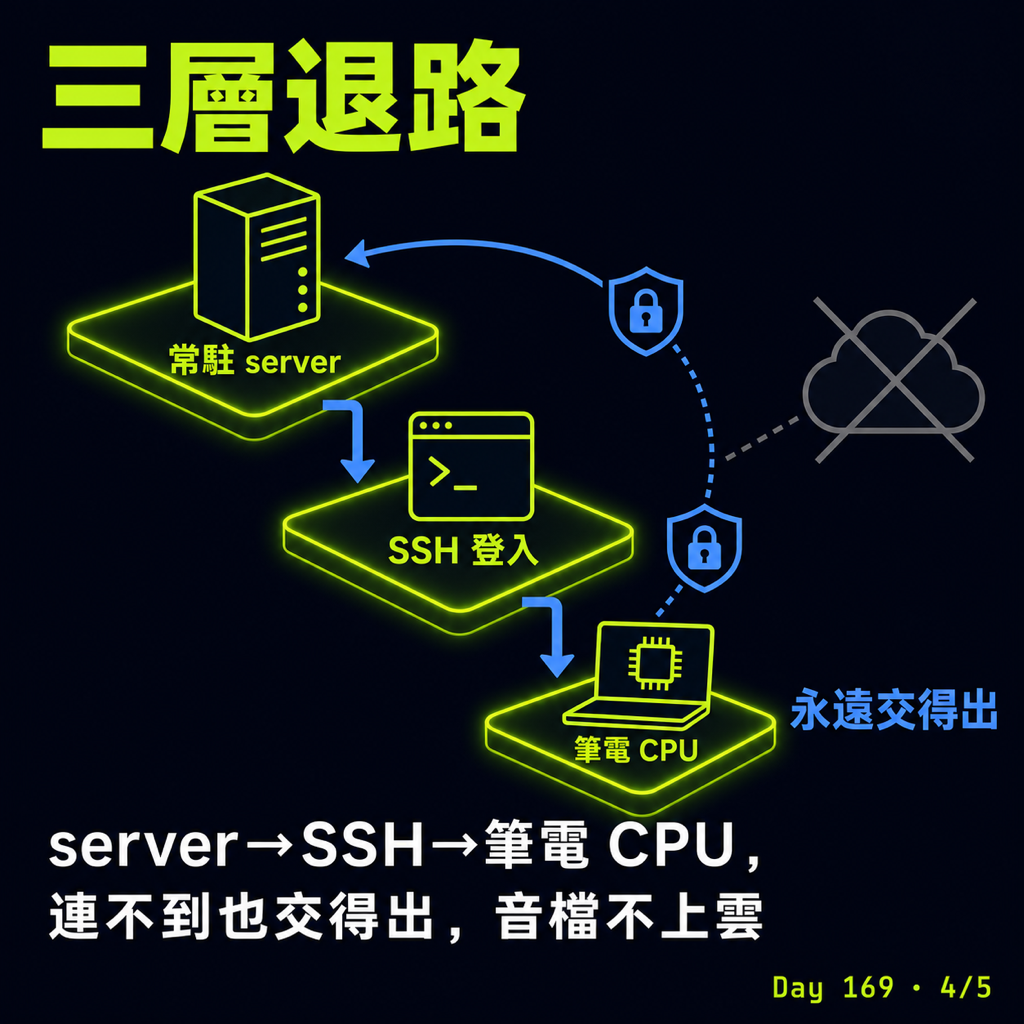
連不到,也不會整個掛掉
我不希望它因為「搬到遠端」就變脆弱,所以設計成三層、會自己往下退:第一層打 MBP 上那個常駐 server,最省記憶體;server 沒開,第二層就用 SSH 直接登入 MBP、自己開一個來跑;萬一連 MBP 都連不到(人在外面、家裡網路斷了),第三層才退回筆電自己用 CPU 慢慢跑。慢歸慢,至少永遠交得出東西。
還有一個我不打算妥協的點:整段過程,音檔都只在我自己這兩台機器之間傳,不經過任何雲端 API。要轉錄的常常是會議、訪談這類不太想外流的內容,這對我來說是底線。
真正想分享的:閒置的好機器,就是你的私人推論伺服器
這件事讓我重新看待手邊的設備。很多人卡在「我的筆電跑不動本地 AI」,但你不一定要為此砸錢換一台更猛的機器,或把資料交給雲端。
如果你手邊剛好有另一台閒著、效能又不差的電腦,把它擺著當一台一直開機的推論伺服器,讓隨身筆電透過一個 skill 透明地呼叫它——你就同時拿到了「筆電的輕便」跟「桌機等級的力氣」,資料還全留在自己手上。我的 MBA 負責輕薄好帶,家裡的 MBP 負責出力,各司其職。
對我來說,這比「換一台更貴的筆電」划算太多了。
不免俗的定期打個廣告:
最近開始做免費的一對一諮詢,幫你把 AI 接進自己的工作流——有需要的話可以約:https://www.dawsonwang.com/