讓 AI 讀 LINE 把案子做對




如果你跟我一樣,手上的案子幾乎都靠 LINE 在溝通,那你大概也遇過這個狀況:客戶的需求、一改再改的細節,全散在某個群組或私訊裡,做到一半還得回頭翻,漏掉一句就可能做錯方向。
這篇講的,就是我怎麼讓 AI 直接讀完整段 LINE 對話、把它當成做事的依據——少漏需求、少記錯,交出去的東西更貼近客戶真正要的。
我把自己在用的工具整理成了公開的開源專案:line-cua-mcp。它的 "為什麼" 我在 Day 98 和 Day 172 講過了,這篇只講對你有用的部分:它能做什麼、我平常怎麼用。
它現在能做什麼
讀訊息:直接讀 LINE 在本機那份加密資料庫,全程在背景進行。不搶滑鼠、不搶你正在打字的視窗,LINE 沒開著也能讀,而且讀的是完整歷史,不是畫面上看得到的那幾則。
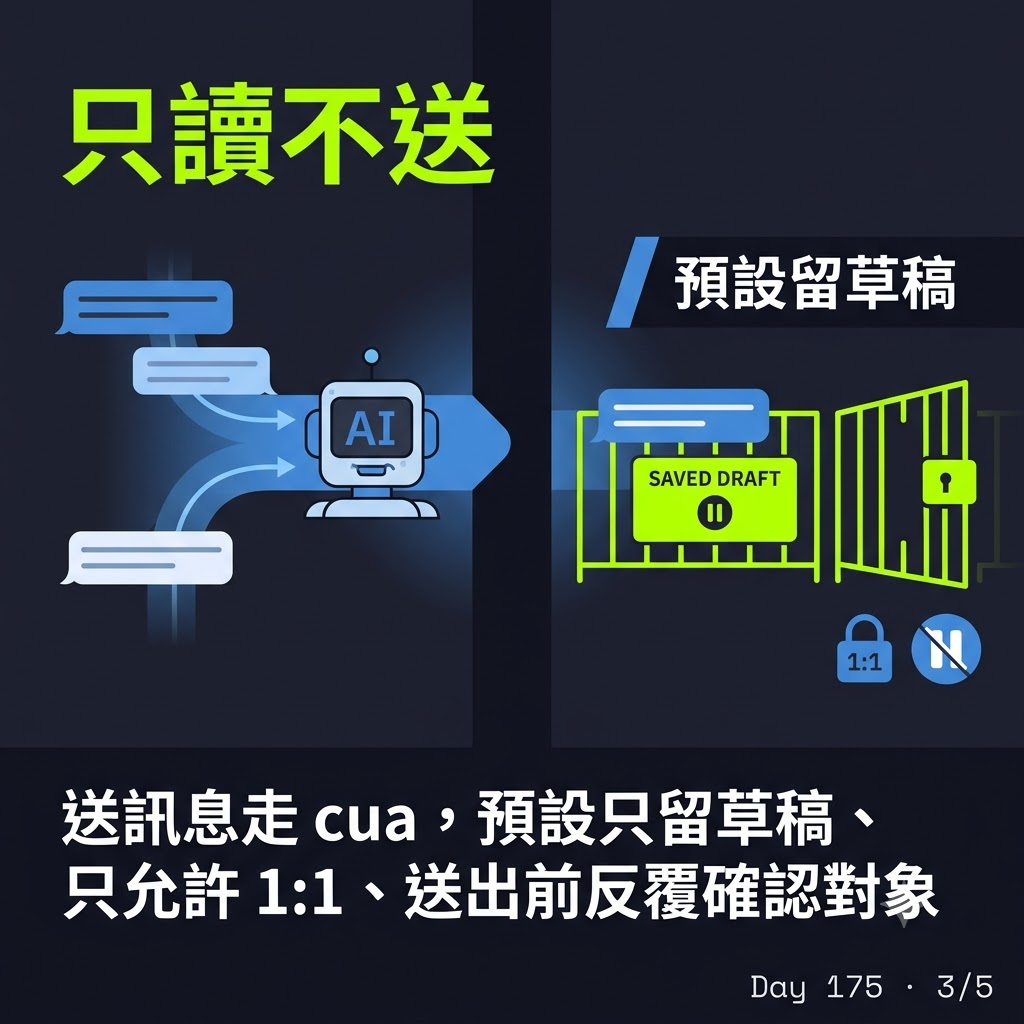
送訊息:這條還是得透過 LINE 介面,走的是 Day 172 講的 cua,不亂動你的游標。而且我把它設得很龜毛——預設只留草稿不直接送、預設只允許 1:1、送出前反覆確認對象。送錯人的代價太高,我寧願它多擋幾次。
裝進 Claude Code 之後,AI 就多了 "讀 LINE、查歷史、必要時送訊息" 這幾個能力。細節都在 README,這裡不重貼。
我平常怎麼用
我自己最常用的,是包在上面的一個 skill:line-sync。
在某個客戶專案底下,直接打:
/line-sync "小明"
它就把我跟小明的完整對話從本機 DB 拉出來,存成這個專案裡的一個 markdown 檔,例如 conversations/line-小明.md:每行都有時間、有真名、依日期分段,每次都整份重新生成。
重點是下一步:寫 prompt 的時候,我直接把這個檔 @ 進去當 context。AI 手上有了完整對話,產出就明顯更貼近客戶實際講過的話——不會漏掉只在 LINE 提過一次的需求,也不會把上禮拜說的跟今天改的搞混。
這種 "對話即 context" 對我來說才是它真正的用處。line-sync 永遠只讀不送。
而且案子的細節,幾乎全藏在這些對話裡。我最近在準備的一份簡報、之前接的一個軟體開發案,需求其實都散在來回的訊息中間,從來沒有人會幫你整理成一份乾淨的規格。
有些還不是打字交代的,是直接講電話講完的。這種我會搭配 Day 169 寫過的 /transcriber,把通話錄音轉成逐字稿,一樣丟給 AI 讀。不管原本是文字還是語音,最後都變成同一種東西:AI 看得懂的原始紀錄。
這背後是一個我越來越相信的做事方式:有了 AI,就別再自己當翻譯器了。以前我們習慣先把對話消化、轉述、整理成 "給 AI 看的版本",等於自己先把事情做掉一半;更聰明的做法,是把最原始的對話直接當成原料丟給它,讓它從第一手資料幫你完成任務。
適合誰、要注意什麼
先講清楚:這是 macOS-only 的實驗性個人工具,不是給一般使用者的產品。它會讀你本機完整的 LINE 歷史,請只在自己的 Mac、自己的帳號、自己的資料上用。它也不是官方工具,讀本機資料庫、操作 desktop client 可能踩到 LINE 的服務條款,這點我不會幫它粉飾。
比較適合的人:已經在用 Claude Code、知道自己在做什麼、手上又真的有一堆 LINE 對話要整理。如果只是偶爾請 AI 回一兩句,沒必要使用。
為什麼還是開源
從 Day 98 到今天,其實都在解同一件事:台灣很多工作溝通就在 LINE 裡,AI 碰不到,就永遠少一塊現場資料。但碰 LINE 不能只求 "能動"——能在背景讀、不打斷我、送訊息前盡量別出錯,這些才是我想驗證的。開源出來,至少有一份可以被檢查的實作。
少一點魔法,多一點看得見的邊界。
最近開始做免費的一對一諮詢,幫你把 AI 接進自己的工作流——有需要的話可以約:https://www.dawsonwang.com/
相關: Day 98:用 AI 讀 LINE 訊息?這個工具讓你不用自己翻對話紀錄 Day 172:AI 幫我用 LINE 可以,霸佔我的電腦不行 GitHub:https://github.com/andrew54068/line-cua-mcp